Here’s a recording of a woman reciting a line from the Catalan poem La Vaca Cega:
Suppose that you wanted to take the recording and change the quality of the voice — change it into a male-sounding voice, for instance. How would you go about it? I did this recently for an online audio processing course I took, and since the process touches not just on how audio transformation works, but also on the physics of the human voice, I thought I’d talk about it in this post.
Playing the Recording More Slowly
You might guess that to change the female voice in the recording to a male one, we would have to make it lower in pitch. Most women speak at frequencies of around 165 to 255 Hz, while most men speak at frequencies of 85 to 180 Hz — so men have voices that are around 1.6 times lower on average. As we saw in the previous post, this is because men tend to have thicker vocal cords, which vibrate at lower frequencies.
Let’s take a look at the waveform of a section of the recording, showing how loud the sound is at each point in time:
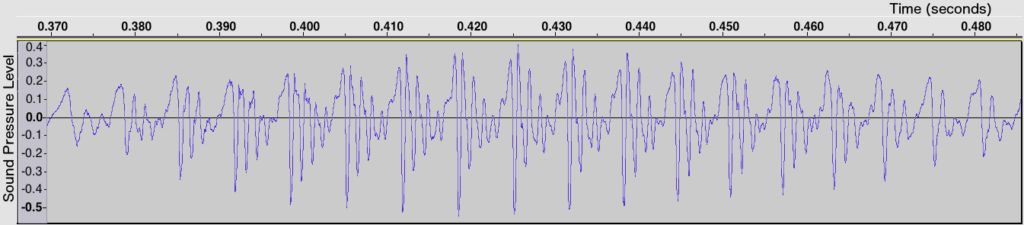
The simplest way to lower the frequency of this sound would be to stretch out its waveform. Let’s stretch it out by a factor of 1.6 along the time axis:
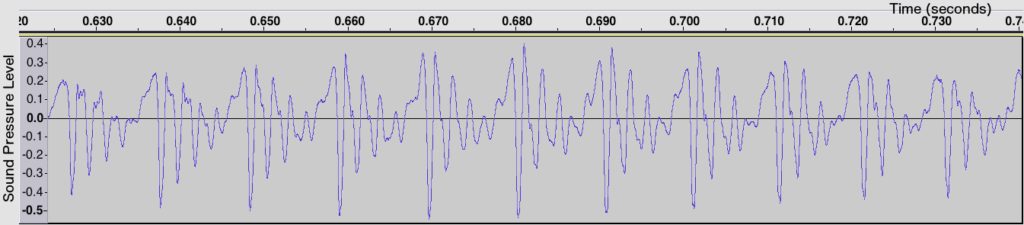
Now each undulation of the wave lasts 1.6 times longer, so the frequency of the wave has decreased by the same factor. The result sounds like this:
Well, the voice is certainly speaking at a lower pitch, but it’s also speaking more slowly! That’s all right if it’s the effect we’re going for, but perhaps we want it to speak at the same tempo as the original recording, to portray the same mood.
Manipulating the Spectrum
To lower the voice without changing its speed, we have to do something rather more complicated. In a previous post I talked about the Fourier theorem, which states that all sounds can be broken down into sine waves of varying frequencies, by applying a mathematical algorithm called the Fourier transform. Doing so allows us to obtain a sound’s spectrum, which shows us all the frequencies that are present in it, as well as how much of each frequency there is. Here’s the spectrum of a small segment of our speech recording:
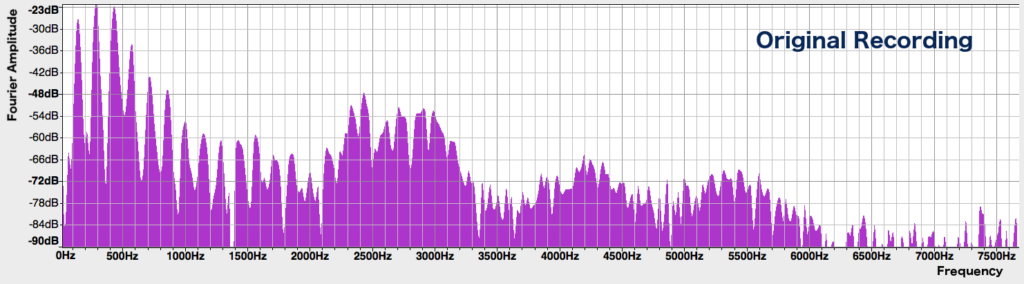
Now that we can clearly see the frequencies present in the sound, we can directly manipulate them by squishing the spectrum along the horizontal axis so that all the frequencies are 1.6 times lower, while keeping the height of each peak unchanged:
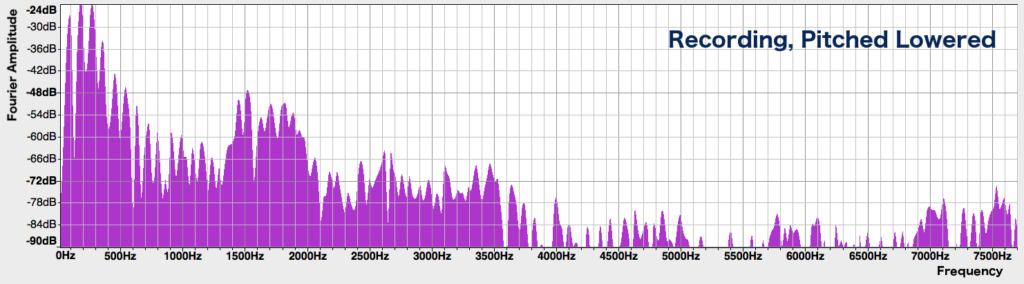
Then we can convert this back into a sound waveform by doing the opposite of the Fourier transform. I’ve illustrated all this on only one segment of the sound, but to transform the whole sound, we’d have to repeat the process of obtaining the spectrum, squishing it, and converting it back to sound for consecutive segments that make up the recording. The result sounds like this:
That still doesn’t sound that great, does it? Though we’ve managed to both lower the pitch and keep the speed of the original speech, the voice now has this weird inhuman quality to it. It’s a quality that you sometimes hear in special effects in music, but doesn’t sound quite natural.
The Shape of the Spectrum
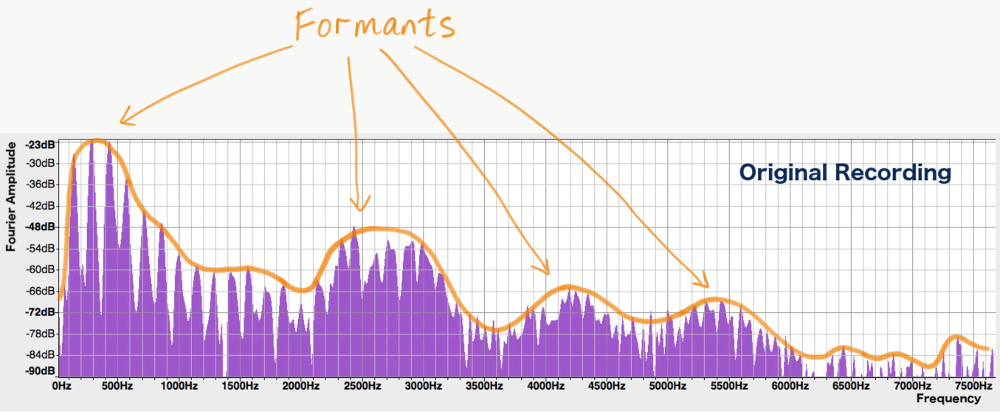
To figure out what’s wrong, let’s take a closer look at the spectra of the sounds. We see successive peaks that are evenly spaced, indicating the harmonics of the sound. But if we take a step back and look at the overall shape of the spectrum, we see that there are bigger hills and valleys in it, marked out by the orange line in the following pictures:

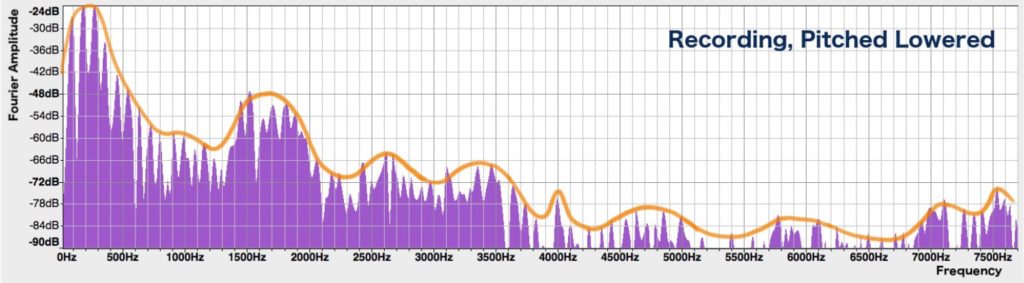
The overall shape of a spectrum is called the spectral envelope, and the mounds in the envelope are called formants. It turns out that the positions of the formants play a big role in how we perceive a sound. We can distinguish different vowels, for instance, because each vowel has a unique set of formant frequencies (more on that in a future post).
More importantly for our problem, male and female voices also have, in general, different formant frequencies and spectral envelopes. To understand why, we need to know why the formant mounds are present in a voice’s spectrum in the first place. In the previous post we saw that the sound that is produced by our vocal cords sounds like a buzz. It has a spectrum that looks like this:
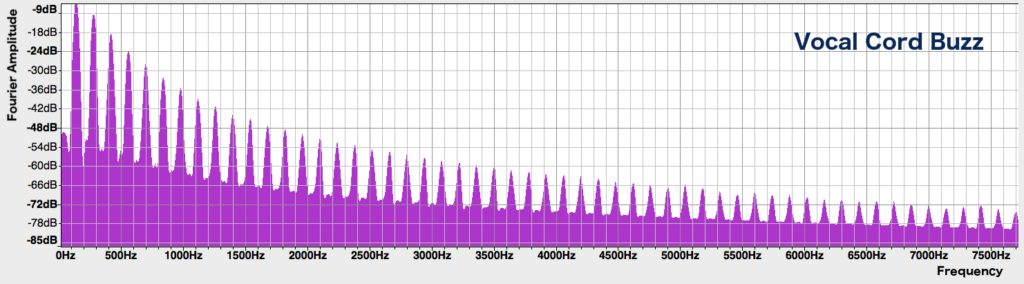
Its general shape slopes downwards smoothly, with no formant bumps. When this sound goes through the vocal tract (the oral and nasal cavities), however, it is modified to produce different vowels and consonants. It is the presence of the vocal tract that introduces the formants. How? The answer has to do with a phenomenon called resonance, which describes how objects have certain natural frequencies (called resonant frequencies) at which they like to vibrate. A large object, such as a guitar, tends to vibrate at lower frequencies than a smaller object, such as a ukulele.
The vocal tract, which is a cavity of a certain size and shape, also has resonant frequencies. These resonances act as a filter for the sound generated by the vocal cords, picking out certain ranges of frequencies, and suppressing others. This causes the hills and valleys in the spectral envelope.
Since men generally have larger vocal tracts than women, their voices have lower formant frequencies. Crucially, however, the ratio of male and female formant frequencies is not as great as the ratio of their speaking fundamental frequencies (i.e. the frequencies at which their vocal cords vibrate). While the fundamental frequency of men’s speaking voices is about 1.6 times lower than that of women, their formant frequencies are only about 1.1 times lower on average, as one can estimate from this table.
Let’s try to take this into account as we manipulate the recording. As before, we take the spectrum and squish it by a factor of 1.6 along the horizontal axis, so that the peaks of the harmonics are 1.6 times lower in frequency. But now, we will also re-adjust the height of each peak so that the formant mounds are only 1.25 times lower in frequency than in the original spectrum. (I chose 1.25 because it seemed to give the best-sounding result in this case.) Here’s the result:
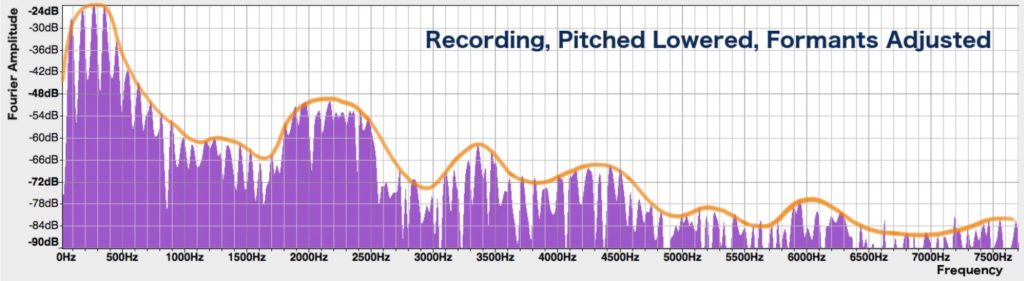
That sounds a lot more natural! A tad metallic, perhaps — possibly due to artifacts that were introduced when digitally altering the spectrum and piecing the sound back together from consecutive small segments.
This process that we’ve just gone through is a simplification, of course. If we were to compare a real male speaker to a female one, we would find that their formant frequencies don’t always differ by a single ratio. Instead, the formant frequencies depend on which vowel is being pronounced, as well as the unique vocal characteristics of each speaker. They can also be controlled by the speaker depending on the mood or tone quality that they wish to achieve. The spectral envelope and formant frequencies are part of the timbre of a person’s voice that we discussed in a previous post, and play a big role in allowing us to recognise the voices of different people.
Next post: What formants have have to do with the phenomenon of helium voice, the chipmunk-like sound that people get when they inhale helium.
Leave a Reply
5 Comments on "Digitally Transforming a Female Voice to a Male Voice"
Hi!
Can you also do this in reverse? Change a male voice into a female voice? The frequency of my voice changed (due to trauma) to the frequency of male speech, even though I don’t sound terribly masculine. I think … I would like to know if a digital reversal would sound like my original voice. Please contact me by email.
What program did you use for the sound manipulation after the initial slowing down?
Amazing and brilliantly mastered …….
what program do you use to turn female voice into neutral? I need this
you tricked me didnt you, it was the female voice that was the modified one, not the male. so its not metallic, i was just hearing things.