
A year ago, a new speech synthesis system called WaveNet was presented by Google’s DeepMind, an artificial intelligence company. As its name suggests, WaveNet generates speech by using neural networks to predict what the sound wave of a sentence should look like. I thought this was interesting because it’s such a counterintuitive way to produce speech sounds.
WaveNet in Action
In this post I’ll explain the odd way in which WaveNet works. Along the way, I’ll also describe more traditional speech synthesis methods, as well as give a brief introduction to neural networks.
Speech Synthesis: How it’s Usually Done
Let’s start with some background on modern techniques for creating artificial speech. There are two primary methods. In the first and more intuitive one, you take existing recordings, and chop them up into little segments — fragments of words. Then you string these bits back together to form whatever you want the computer to say. This method is called concatenative or unit selection synthesis.
Unit selection synthesis can produce somewhat natural-sounding speech, but doesn’t give us much control over expression or vocal qualities — these are limited by the database of recordings that we use. Also, it’s not a simple task to choose fragments that both fit the word/sentence context, and join together well. This sometimes leads to glitches and odd rhythms. That said, the most advanced unit selection systems, such as Apple’s latest incarnation of Siri in iOS 11, can sound very good.
Siri, iOS 10
Siri, iOS 11
The second synthesis method looks at things on a more abstract level, and doesn’t directly use recorded samples. Instead, it generates speech sounds from scratch, based on models of how the human voice works. Often, this involves generating a source sound like the one produced by our vocal cords, and using filters to shape its spectrum (see these previous posts on the human voice).
When this method was first developed, people would figure out the parameters of the model by manually studying speech recordings. Nowadays, though, it’s more common to use machine learning techniques — the model automatically learns its parameters from existing recordings which have been mapped to text.
This parametric synthesis method gives us more freedom to vary the sounds, but tends to sound more artificial than concatenative synthesis (in part because it’s limited by how representative its models are).
Stephen Hawking’s voice uses the DECtalk synthesiser, first developed in the 1980s. This system is based on formant synthesis, which was the precursor to modern parametric synthesis.
WaveNet
What about WaveNet? It approaches the problem from a completely different angle, by directly considering the sound wave. Modern digital recordings are sampled, which means that every, say, 1/16000th of a second, the system outputs a number that tells you how high the sound wave is at that point in time:
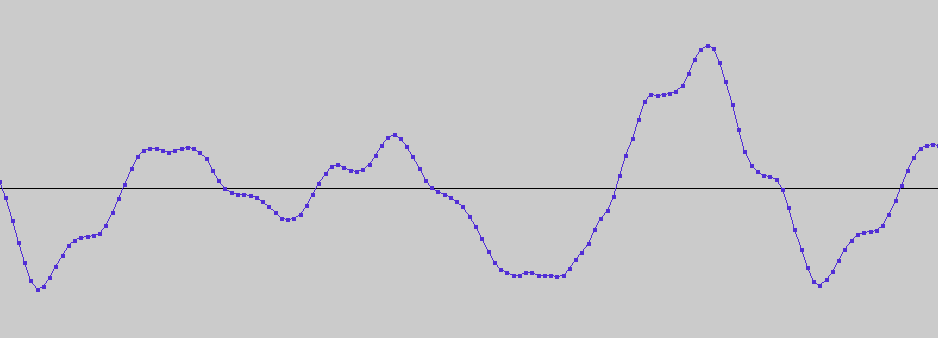
WaveNet generates sound by building the sound wave sample-by-sample. At each time step, the neural network predicts the height of the wave by looking at the 4000 or so time steps that came before it.
Before the software can start the building process, however, it has to first learn the patterns present in speech: how, in existing speech recordings, the value of a sample depends on previous samples. It also learns how this dependence is affected by what letter or word is currently being pronounced, and by other factors such as syllable stresses and tone of voice. It then uses the patterns it has learnt to generate speech.
Micro-Management
Why do I find this a strange way to do things? Well, the two standard speech synthesis methods that I described earlier look at the sound on a fairly long time scale — a few milliseconds at the shortest, which corresponds to about 100 time steps in a digital file with 16000 samples per second. This makes sense, because that’s about the time scale over which speech sounds change. Besides, the information in a sound wave is only meaningful if we look at segments of a certain length, because what’s important is the pattern the wave makes — how many undulations there are in a certain time.
But WaveNet looks at things on a much smaller time scale, 1/16000th of a second, sample by sample. It’s as if it were trying to create a painting by laying down one molecule of paint at a time — it really doesn’t matter where each individual molecule is, as long as the cluster that makes up each brush stroke is in the right place!
Counterintuitive or not, it works! The WaveNet research team tested their technique by asking people to rate how realistic various sentences sounded. Each sentence had several versions — spoken by a real person, generated by WaveNet, or generated by more traditional synthesis methods. They found that WaveNet sentences were perceived to be significantly more natural-sounding than traditionally synthesised ones, though not as realistic as real speech.
Click to Expand: Neural NetworksNeural networks are all the rage nowadays in any field that involves getting a computer to learn things. They were inspired by the neurons in the human brain, which are connected to one another to form a network. Each neuron can send and receive electrical signals, allowing it to communicate with its neighbours.
Artificial neural networks deal with numbers instead of electrical signals. Each neuron takes in some numbers, applies a mathematical function to them, and spits out a different number. Its output is then fed to adjacent neurons, after being multiplied by a factor called a weight. Each pair of connected neurons has its own weight.
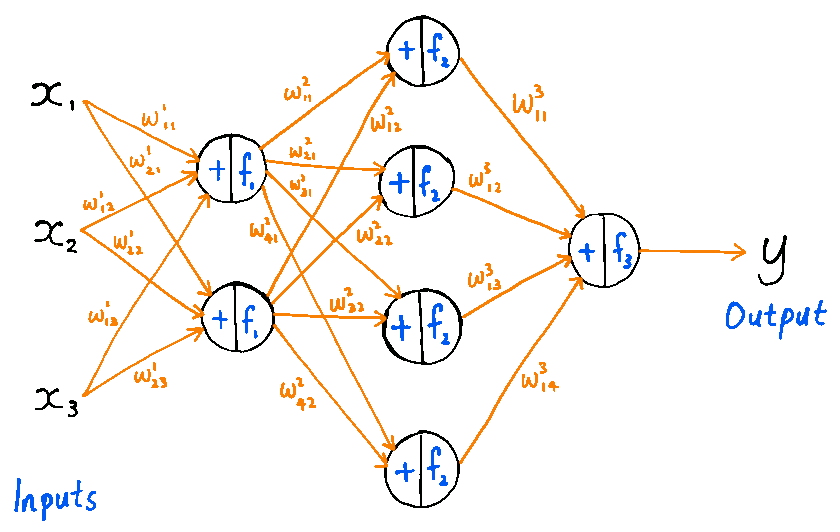
When an input (such as a series of numbers) is fed into the network, the numbers pass through the network structure and come out on the other side as a bunch of different numbers. For example, let’s suppose we were designing a network to generate speech waveforms, sample-by-sample. At each time step, our input numbers could be the value of the 4000 previous samples, together with numbers that represent which word is currently being pronounced. The output would be a single number that tells us the value of the waveform at the next time step. After predicting this sample, we would “shift” the network forward by one time step to predict the following sample, and so on.
Before they can be of any use, neural networks must be trained on data. So we need a set of data for which we know both the input numbers and the output numbers (in our example, we would use existing speech recordings). When training, the neural network varies its weights, in order to produce (for each input data point) an output that is as close as possible to the correct value. Once it’s trained, we fix the weights and use the network to make predictions about data that it hasn’t yet seen.
Over the last 10 years or so, computers have become powerful enough to allow us to build increasingly complex neural networks. They can now perform complicated tasks such as face and voice recognition, medical diagnosis, and fun things like making a photograph look like a painting.
WaveNet in Action
When it was first announced last year, WaveNet had a significant downside: it required too much computing power, making it impractical for day-to-day use. Since then, however, the DeepMind team has managed to speed up the algorithm so that it’s 1000 times faster than before, all while producing higher-quality speech. Just last month, WaveNet’s voices were incorporated into Google Assistant:
WaveNet in Google Assistant
Because WaveNet generates raw waveforms, it’s very versatile. The synthesiser manages to mimic sounds like breathing and lips parting, for example. It also isn’t limited to producing human speech — the researchers got it to learn from musical recordings as well, including a set of solo piano pieces. You can hear snippets of the results on their blog page.
Those snippets certainly sound like a piano, and seem harmonious enough (though I thought all of them sounded strangely similar in terms of musical style). Because the neural network can only keep track of the waveform over several seconds at most, it isn’t able to generate a coherent melody or chord progression — so at the moment its ability to compose music is probably limited.
The whole thing is still pretty cool, though.
Leave a Reply
Be the First to Comment!